Graceful Upgrades To Gunicorn Apps
2023-07-13
Frappe app updates are managed using the bench CLI and work really well for the most part.
However, a bench restart is disruptive and necessitates downtime. Quite a few of our apps can't afford downtime outside of specific,
short (<30 minute) windows at odd off-peak hours.
For hotfixes in such cases, I have now started using a built-in feature of Gunicorn
to do zero downtime updates when making Python code changes.
The documentation link above explains the flow quite well. Here's my workflow:
git pullinside the app directory, e.g.frappe-bench/apps/iotready_otp- Look up the PID using
htopafter enablingtreeview (F5) - the top PID from which the branches (workers) begin is the one we are after - Send the following signals in sequence (you can, of course, send these from within the
htopUI withF9):kill -USR2 <pid>kill -WINCH <pid>kill -TERM <pid>
And that's it - workers are launched running the new Python code and existing workers will shutdown and exit once running requests are closed. Eventually the master Gunicorn process exits too.
The documentation describes steps to revert back too (before sending the TERM signal). This is what your htop will look like during this process.
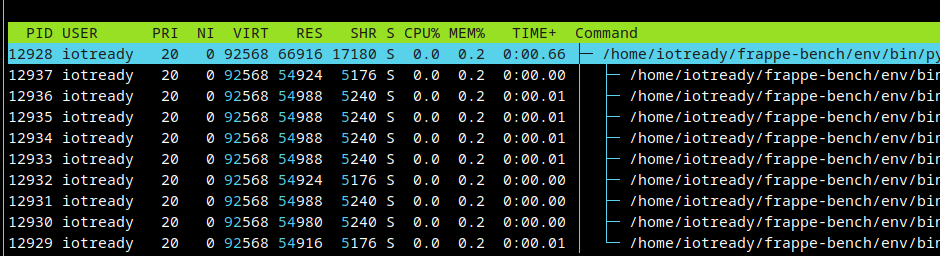
Pre USR2
I have 10 workers branching from the master PID (12928).
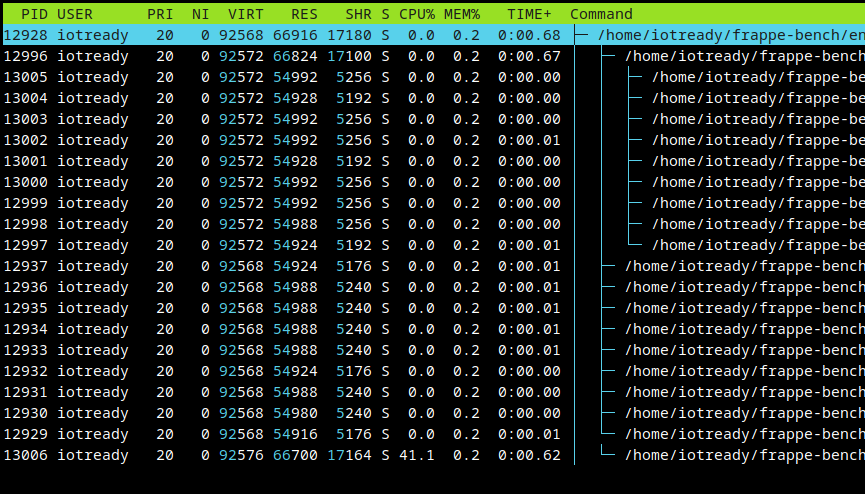
Post USR2
A second master PID (12996) has been launched from the previous PID. This new Gunicorn process has its own workers.
Post WINCH
Looks the same as Post USR2 except the old workers have stopped taking requests.
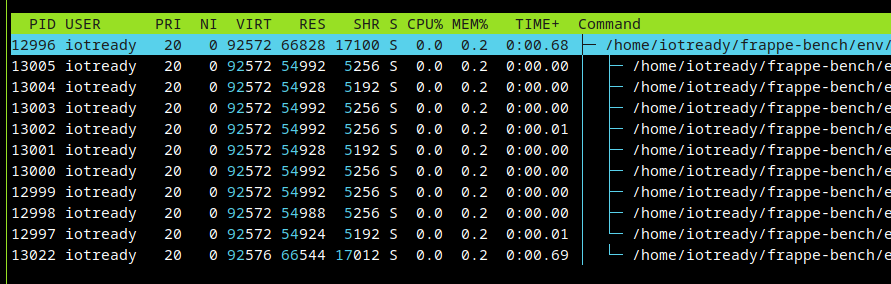
Post TERM
The old PID is gone and all we are left with is the new PID.
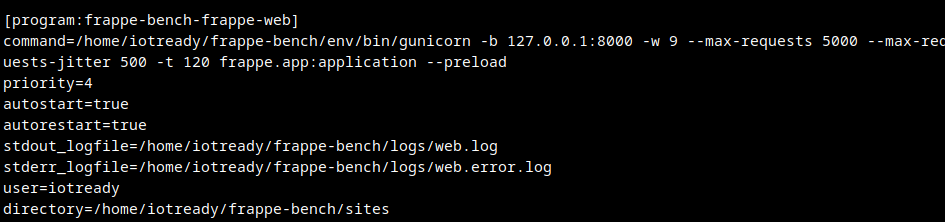
Making this a tad simpler
The reason we need all these steps is because Frappe uses a --preload flag by default when launching Gunicorn. This is configured
inside the frappe-bench/config/supervisord.conf file.
Without the --preload flag, Gunicorn will do all of the above with just the HUP signal. However, sending a HUP also means that you
will lose the ability to revert.
# Edit the supervisor.conf file to remove --preload
# Reload the supervisor configuration
sudo supervisorctl reload
# Wait for processes to restart
sudo supervisorctl signal HUP frappe-bench-web:frappe-bench-frappe-web
I have chosen to keep --preload and use the manual process as it gives me a bit more control and I can see the changes happening.
Frappe best practices
There are a few other Frappe working practices I follow to help with easier/graceful updates:
- Use versioning for APIs, e.g. new features or breaking changes go into
api_v2.pyso that the caller calls/api/method/app.api_v2.function - Expand and then contract for schema, e.g. when replacing or renaming fields, I add the new field, deploy it and once all clients (e.g. Android apps) are using the API and schema, I may remove the old fields.
- Use field/version based conditionals in document hooks.